모니터링 확장 설치
Metrics Server만으로는 부족하신가요? 과거 데이터를 분석하거나, 알림을 설정하거나, 더 상세한 메트릭이 필요하다면 모니터링 확장을 설치하세요. Prometheus와 cAdvisor로 전문적인 모니터링 환경을 구축할 수 있습니다.
- 지난 주 대비 리소스 사용량 트렌드를 분석하고 싶을 때
- CPU가 80%를 넘으면 Slack 알림을 받고 싶을 때
- Container별 네트워크 사용량을 확인하고 싶을 때
모니터링 구성요소
Metrics Server vs 모니터링 확장
각 도구의 역할과 특징을 비교해 보겠습니다.
- Metrics Server: 기본 리소스 메트릭을 제공합니다. 실시간 데이터만 저장하며, HPA와 kubectl top 명령에 사용됩니다.
- cAdvisor: Container별 상세 메트릭을 수집합니다. 실시간 데이터만 저장하며, 상세 모니터링에 활용됩니다.
- Prometheus: 메트릭을 수집, 저장, 쿼리합니다. 장기 저장이 가능하여 트렌드 분석과 알림에 사용됩니다.
- HPA만 필요하면: Metrics Server만 설치
- 상세 모니터링이 필요하면: Metrics Server + cAdvisor 설치
- 히스토리 분석과 알림이 필요하면: 모두 설치
설치 권장 순서
단계별로 설치하면 문제 발생 시 원인을 파악하기 쉽습니다.
- Metrics Server (필수): HPA와
kubectl top명령의 기반입니다 . - cAdvisor (권장): Container별 상세 메트릭을 수집합니다 .
- Prometheus (선택): 장기 데이터 저장과 알림이 필요할 때 설치합니다 .
사전 요구사항
- Kubernetes 클러스터가 KIWI에 등록되어 있어야 합니다 .
- 충분한 클러스터 리소스 (Prometheus 설치 시)
권한 안내: 이 기능에 접근할 수 없다면 기관 관리자에게 권한을 요청하세요.
cAdvisor 설치
cAdvisor는 각 노드에서 컨테이너 리소스 사용량을 수집합니다.
Step 1: 모니터링 탭 이동
- [런타임 환경] 페이지에서 대상 클러스터를 선택합니다 .
- 클러스터 상세 페이지에서 모니터링 탭을 클릭합니다 .
Step 2: 사전 검사
- 모니터링 확장 버튼을 클릭합니다 .
- 사전 검사(Preflight Check)가 자동으로 실행됩니다:
- 클러스터 연결 상태
- 노드 접근 가능 여부
- 기존 설치 여부
Step 3: cAdvisor 설치
- cAdvisor 설치 옵션을 선택합니다 .
- 설치 옵션을 확인합니다:
- 포트: 기본값 8080
- 리소스 제한: CPU/메모리 제한 설정
- 설치 버튼을 클릭합니다 .
Step 4: 설치 확인
설치가 완료되면:
- 각 노드에 cAdvisor DaemonSet이 배포됩니다 .
- cAdvisor 상태: Running 표시
- 노드별 컨테이너 메트릭이 수집됩니다 .
Prometheus 설치
Prometheus는 메트릭을 수집하고 장기 보존합니다.
Step 1: Prometheus 설치 선택
- 모니터링 확장 모달에서 Prometheus 설치를 선택합니다 .
- 설치 옵션을 설정합니다 .
Step 2: 스토리지 설정
Prometheus는 메트릭 데이터를 저장하기 위한 스토리지가 필요합니다:
- EmptyDir (테스트 환경 권장): 임시 스토리지로, Pod가 재시작되면 모든 데이터가 손실됩니다. 빠른 테스트나 데모 용도로만 사용하세요.
- PVC (운영 환경 권장): PersistentVolumeClaim을 사용하는 영구 스토리지입니다. Pod가 재시작되어도 데이터가 유지되며, 운영 환경에서 필수적으로 사용해야 합니다. StorageClass와 PV가 사전에 구성되어 있어야 합니다.
- 외부 스토리지 (대규모 환경 권장): Thanos, Cortex 등 외부 스토리지 시스템과 연동합니다. 대용량 데이터 저장과 고가용성이 필요한 대규모 환경에 적합합니다.
Step 3: 리소스 설정
Prometheus 리소스 요청을 설정합니다:
- CPU: 최소 250m이 필요하며, 일반적인 환경에서는 500m을 권장합니다. 대규모 클러스터(20개 이상 노드)에서는 1000m(1 CPU) 이상을 할당하세요.
- 메모리: 최소 512Mi가 필요하며, 권장값은 1Gi입니다. 메모리가 부족하면 OOM(Out of Memory)으로 Pod가 재시작되므로, 대규모 환경에서는 2Gi 이상을 할당하세요.
- 스토리지: 보존 기간과 수집 대상에 따라 결정됩니다. 최소 10Gi, 권장 50Gi이며, 장기 보존이 필요한 대규모 환경에서는 100Gi 이상을 확보하세요.
Step 4: 보존 기간 설정
메트릭 데이터 보존 기간을 설정합니다:
- 15일 (기본): 단기 분석용
- 30일: 월간 트렌드 분석
- 90일: 분기별 분석
- 365일: 연간 분석 (대용량 스토리지 필요)
Step 5: 설치 실행
- 설정을 확인하고 설치 버튼을 클릭합니다 .
- 설치 진행 상황이 표시됩니다:
- Prometheus Operator 설치
- Prometheus 인스턴스 생성
- ServiceMonitor 구성
- 설치 완료 메시지를 확인합니다 .
설치 상태 확인
상태 표시
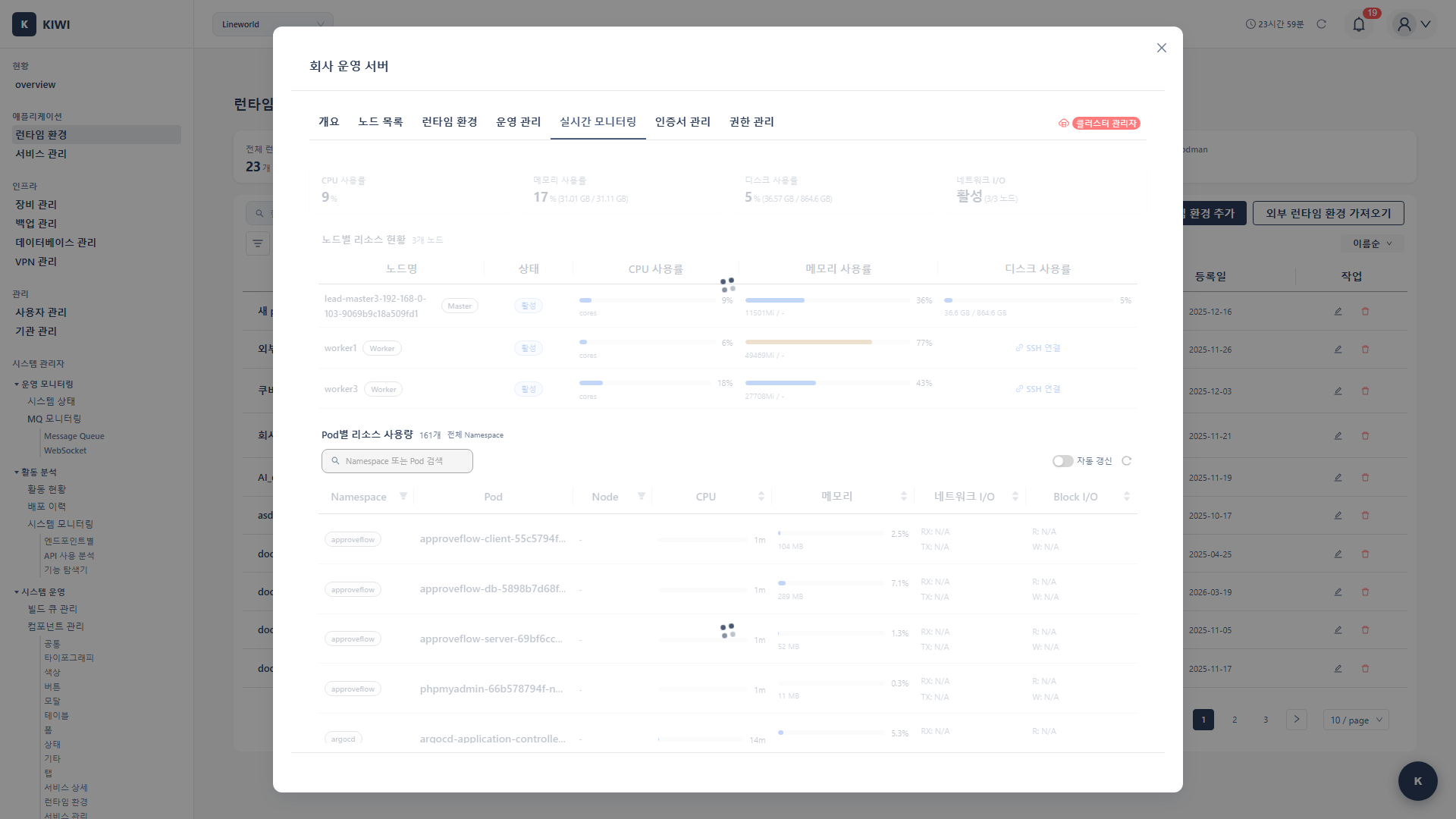
모니터링 탭에서 각 구성요소의 상태를 확인할 수 있습니다:
- 미설치: 해당 모니터링 구성요소가 아직 설치되지 않은 상태입니다. 설치 버튼을 클릭하여 설치를 시작할 수 있습니다.
- 설치 중: 설치가 진행 중인 상태입니다. 완료될 때까지 잠시 기다려주세요. 일반적으로 1-3분 정도 소요됩니다.
- Running: 구성요소가 정상적으로 작동 중입니다. 메트릭 수집이 진행되고 있으며, 대시보드에서 데이터를 확인할 수 있습니다.
- Error: 구성요소에 오류가 발생했습니다. 로그를 확인하여 문제를 진단하고, 필요시 재설치를 시도하세요.
실시간 메트릭 확인
설치 완료 후 KIWI에서 확인할 수 있는 메트릭:
노드 수준:
- CPU 사용률 (%)
- 메모리 사용량 (GB / %)
- 디스크 사용량
- 네트워크 I/O
Pod 수준:
- 컨테이너별 CPU 사용량
- 컨테이너별 메모리 사용량
- 재시작 횟수
클러스터 수준:
- 총 리소스 용량
- 할당된 리소스
- 사용 가능한 리소스
KIWI 대시보드에서 활용
대시보드 위젯
모니터링 확장 설치 후 대시보드에 추가되는 위젯:
- 클러스터 리소스 현황: CPU/메모리 사용률 게이지
- 노드 상태: 노드별 리소스 사용량 차트
- Pod 리소스: 상위 리소스 사용 Pod 목록
- 트렌드 차트: 시간별 리소스 사용량 그래프
서비스 운영에서 활용
서비스 운영 모달에서 실시간 리소스 확인:
- 서비스 목록에서 운영 버튼 클릭
- 리소스 탭 선택
- 실시간 CPU/메모리 사용량 확인
- 히스토리 그래프 확인 (Prometheus 설치 시)
알림 설정 (Prometheus)
Prometheus 설치 시 알림 규칙을 설정할 수 있습니다.
기본 알림 규칙
KIWI는 다음 기본 알림 규칙을 제공합니다:
- HighCPUUsage (Warning): CPU 사용률이 5분 이상 80%를 초과할 때 발생합니다. 애플리케이션 성능 저하가 예상되므로 리소스 확장이나 최적화를 검토하세요.
- HighMemoryUsage (Warning): 메모리 사용률이 5분 이상 85%를 초과할 때 발생합니다. OOM 위험이 있으므로 메모리 누수 점검이나 리소스 증가를 고려하세요.
- PodCrashLooping (Critical): 1시간 내에 Pod가 5회 이상 재시작될 때 발생합니다. 애플리케이션 오류나 설정 문제가 있으므로 즉시 로그를 확인하세요.
- NodeNotReady (Critical): 노드가 NotReady 상태가 될 때 발생합니다. 해당 노드의 Pod가 스케줄링되지 않으므로 즉시 노드 상태를 점검하세요.
알림 수신 설정
- 모니터링 탭에서 알림 설정 버튼 클릭
- 알림 수신 방법 선택:
- Slack: Webhook URL 입력
- Email: 수신자 이메일 입력
- Webhook: 커스텀 Webhook URL
- 저장 버튼 클릭
문제 해결
cAdvisor 설치 실패
- DaemonSet 배포가 실패하는 경우: 노드에 충분한 리소스가 없어 cAdvisor Pod를 스케줄링할 수 없습니다. 설치 옵션에서 CPU/메모리 제한을 낮추거나, 노드의 리소스 상황을 확인하세요.
- 포트 충돌이 발생하는 경우: 기본 포트 8080이 다른 애플리케이션에서 사용 중입니다. 설치 옵션에서 다른 포트(예: 8081)를 지정하세요.
- 이미지 Pull이 실패하는 경우: cAdvisor 이미지를 다운로드할 수 없습니다. 클러스터 노드의 인터넷 연결 또는 프라이빗 레지스트리 설정을 확인하세요.
Prometheus 설치 실패
- PVC 생성이 실패하는 경우: 클러스터에 적절한 StorageClass가 없습니다. StorageClass를 먼저 생성하거나, 테스트 목적이라면 스토리지 옵션을 EmptyDir로 변경하세요.
- OOM(Out of Memory)이 발생하는 경우: Prometheus에 할당된 메모리가 부족합니다. 리소스 설정에서 메모리 제한을 증가시키세요. 권장값은 최소 1Gi입니다.
- CrashLoopBackOff 상태인 경우: 설정 오류로 Prometheus가 시작되지 못합니다.
kubectl logs명령으로 로그를 확인하고, 문제 해결 후 재설치하세요.
메트릭 수집 안됨
- 원인 1: cAdvisor/Prometheus Pod가 Running 상태가 아님
- 원인 2: ServiceMonitor 설정 오류
- 원인 3: 네트워크 정책으로 차단됨
해결 방법:
- Pod 상태 확인:
kubectl get pods -n monitoring - 로그 확인:
kubectl logs <pod-name> -n monitoring - 네트워크 정책 확인
모니터링 구성요소 삭제
cAdvisor 삭제
- 모니터링 탭에서 cAdvisor 상태 옆의 삭제 버튼 클릭
- 확인 대화상자에서 삭제 클릭
- 각 노드에서 cAdvisor DaemonSet이 제거됩니다 .
Prometheus 삭제
- 모니터링 탭에서 Prometheus 상태 옆의 삭제 버튼 클릭
- 확인 대화상자에서 삭제 클릭
- 관련 리소스가 모두 제거됩니다 .
주의: Prometheus 삭제 시 저장된 메트릭 데이터도 함께 삭제됩니다.
베스트 프랙티스
성공적인 모니터링 환경을 위한 권장 사항입니다.
리소스 계획
클러스터 규모에 따라 Prometheus에 할당할 리소스가 다릅니다.
- 소규모 (1-5 노드): CPU 500m, 메모리 1Gi를 권장합니다. 개발 및 테스트 환경에 적합합니다.
- 중규모 (5-20 노드): CPU 1코어, 메모리 2Gi를 권장합니다. 스테이징 또는 소규모 운영 환경에 적합합니다.
- 대규모 (20+ 노드): CPU 2코어, 메모리 4Gi 이상을 권장합니다. 대규모 운영 환경에 적합합니다.
Prometheus가 자주 OOM으로 재시작되거나 쿼리가 느려지면 리소스를 늘려야 합니다.
스토리지 계획
대략적인 스토리지 사용량을 참고하여 용량을 계획하세요.
- 노드당: 약 1-2MB/일
- Pod당: 약 0.5-1MB/일
- 예시: 15일 보존, 10노드, 100 Pod = 약 2-3GB
성능 최적화
모니터링 시스템이 오히려 클러스터에 부담이 되지 않도록 주의하세요.
- 스크레이프 간격: 기본 15초, 대규모 환경에서는 30초 권장
- 보존 기간: 필요한 기간만 설정 (오래 보존할수록 스토리지 필요)
- 레이블 제한: 불필요한 레이블은 제거하여 카디널리티 관리
- 원격 스토리지: 장기 보존이 필요하면 Thanos 같은 외부 스토리지 활용